
En la era de los datos, las empresas constantemente enfrentan desafíos para transformar grandes conjuntos de datos en información valiosa. Los Dashboards interactivos se han convertido en una herramienta fundamental para analizar y visualizar datos de manera efectiva, permitiendo a las empresas tomar decisiones estratégicas y buscar oportunidades de negocio. En este artículo, aprenderemos a crear un Dashboard en Streamlit y Pandas, dos potentes herramientas de Python para el tratamiento y visualización de datos.
Fuente de Datos
Para este ejemplo, utilizaremos un conjunto de datos de ventas minoristas(retail) que contiene información de transacciones de ventas con detalles del contexto y comportamiento de compra. Es importante resaltar que este dataset hace alusión a un conjunto de transacciones ficticias para el año 2023 de una compañía. Este dataset hacer parte de un repositorio público de la compañia Rappi. Puedes descargar el dataset desde el siguiente enlace.
Definición de las métricas clave
Antes de pasar a construir el Dashboard, es importante comprender el conjunto de datos e identificar las métricas clave a las cuales queremos sacarle provecho.
Métricas Claves escogidas
En este tipo de problemas, es importante definir una pregunta principal que queremos responder con el Dashboard. En este caso, nos enfocaremos en responder la siguiente pregunta:
- ¿Cómo diseñar un plan estratégico para 2024 que maximice el rendimiento y aproveche las oportunidades detectadas en 2023?
Para poder responder esta pregunta principal,también debemos plantear una serie de preguntas secundarias que nos permitan responder la pregunta principal. A continuación, algunas preguntas secundarias que podríamos plantear:
- ¿Cuál fue el rendimiento de las ventas en 2023?
- ¿En que momento de la semana deberían estar enfocadas las estrategias?
- ¿En que retails deberíamos focalizar nuestras estrategias?
Exploratory Data Analysis (EDA)
Una vez definidas las métricas clave y las preguntas que queremos responder, necesitamos explorar el conjunto de datos antes de comenzar a construir el Dashboard. Aquí es donde el análisis exploratorio de datos (EDA) juega un papel fundamental.
Exploratory Data Analysis (EDA) es una técnica utilizada para analizar e investigar conjuntos de datos con el objetivo de resumir sus características principales.
Este no es un artículo sobre EDA, así que de manera muy general haremos un análisis exploratorio de los datos para entender su estructura y contenido. Si quieres profundizar en el tema, te recomiendo leer el siguiente artículo: Análisis Exploratorio de Datos (EDA). A continuación, la imagen de los primeros registros del dataset.
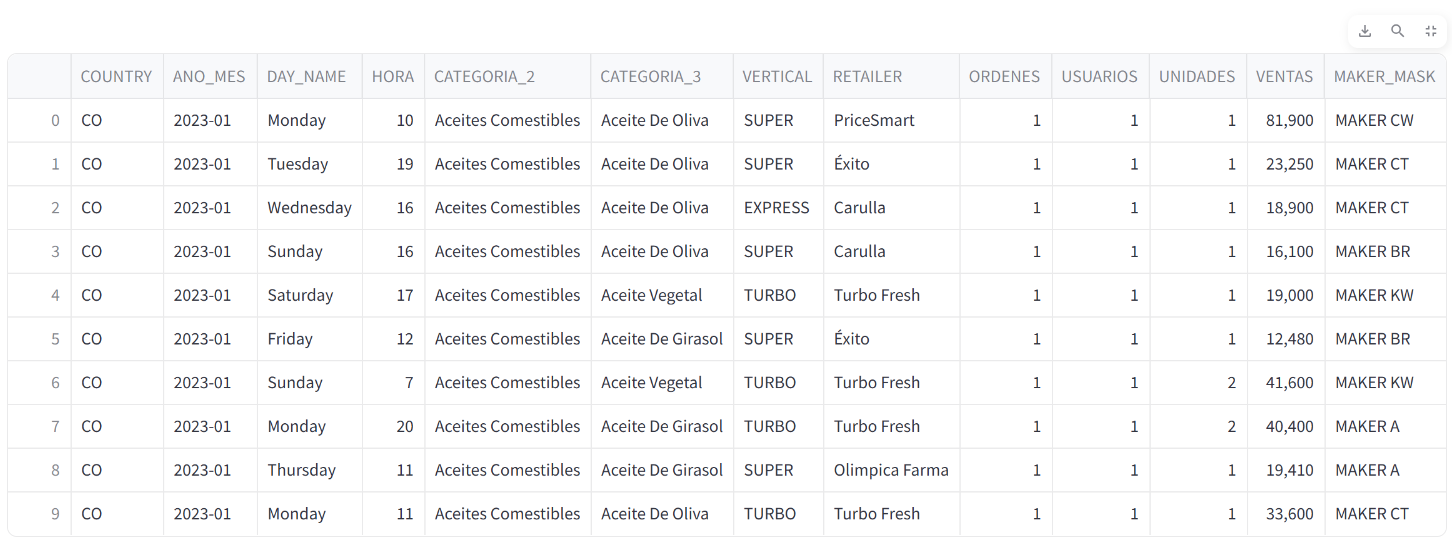 Primeros Registros del Dataset
Primeros Registros del Dataset
De acuerdo con la imagen, podemos identificar las siguientes columnas en el dataset que nos van a ser útiles para responder las preguntas planteadas:
- DAY_NAME: Día de la semana en el que se realizó la transacción (Para identificar el mejor día de la semana para enfocar las estrategias).
- RETAIL: Nombre del retail en el que se realizó la transacción (Para identificar en que retail deberíamos focalizar nuestras estrategias).
- VENTAS: Valor de la venta realizada (Para identificar el rendimiento de las ventas en 2023).
- UNIDADES: Cantidad de productos vendidos (Para identificar el rendimiento de las ventas en 2023).
- CATEGORIA_2 y CATEGORIA_3: Categorías de los productos vendidos (Para identificar las categorías de productos más vendidas).
Una vez identificadas las métricas clave y las columnas relevantes del dataset, estamos listos para comenzar a construir el Dashboard en Streamlit.
Manos a la Obra
Configuración del Entorno de Trabajo
Para comenzar, instalaremos las librerías necesarias para el desarrollo del Dashboard y el tratamiento de datos. En tu entorno de trabajo, ejecuta el siguiente comando para instalar las librerías Pandas y Streamlit.
pip install pandas streamlit plotly matplotlib
Creación del Dashboard
1. Sección Inicial
Para crear el Dashboard, primero debemos importar las librerías necesarias y cargar el dataset en un DataFrame de Pandas. También vamos a agregar algunas configuraciones iniciales al Dashboard, como el título y la configuración de la página.
app.py
import streamlit as st import pandas as pd import plotly.express as px # Configuración de la página st.set_page_config( page_title="Businness Case Dashboard", page_icon="💰", layout="wide", ) # Título del Dashboard st.title("Dashboard - 2023") # Cargar el dataset df = pd.read_csv('data/database.csv')
Importante: A partir del análisis exploratorio de datos, identificamos una columna AÑO_MES que contiene la fecha de la transacción en formato YYYY-MM. Vamos a transformar esta columna a dos nuevas columnas AÑO y MES para facilitar el análisis de las ventas por mes. Esto lo haremos en el siguiente bloque de código.
app.py
# Crear una nueva columna con el año y mes df[['ANO', 'MES']] = df['ANO_MES'].str.split('-', expand=True)
Lo siguiente que vamos a hacer es crear una sección inicial en el Dashboard para mostrar una descripción general de los datos. como el número de transacciones y el total de ventas realizadas en 2023.
app.py
# Agregar un subtitulo st.subheader("Información General") # Crear una sección con dos columnas y 2 filas col_1, col_2 = st.columns(2,gap='medium') col_3, col_4 = st.columns(2,gap='medium') #Calcular y mostrar el total de ventas total_sales = df['VENTAS'].sum() col_1.metric( label="Total Ventas", value=f"{total_sales:,} COP", border=True ) #Calcular y mostrar el número de transacciones number_transaction = len(df) col_2.metric( label="No. de Transacciones", value=f"{number_transaction:,}", border=True ) # Calcular y mostrar el mejor y peor retailer sales_by_retailer = df.groupby('RETAILER')['VENTAS'].sum().reset_index().sort_values(by='VENTAS',ascending=False) # Agrupar por retailer y sumar las ventas best_retailer = sales_by_retailer.iloc[0] # Mejor retailer worst_retailer = sales_by_retailer.iloc[-1] # Peor retailer # Mostrar el mejor Retailer col_3.metric( label=f"Mejor Retailer: {best_retailer['RETAILER']}", value=f"{best_retailer['VENTAS']:,} COP", border=True, ) # Mostrar el peor Retailer col_4.metric( label=f"Último Retailer: {worst_retailer['RETAILER']}", value=f"{worst_retailer['VENTAS']:,} COP", border=True, )
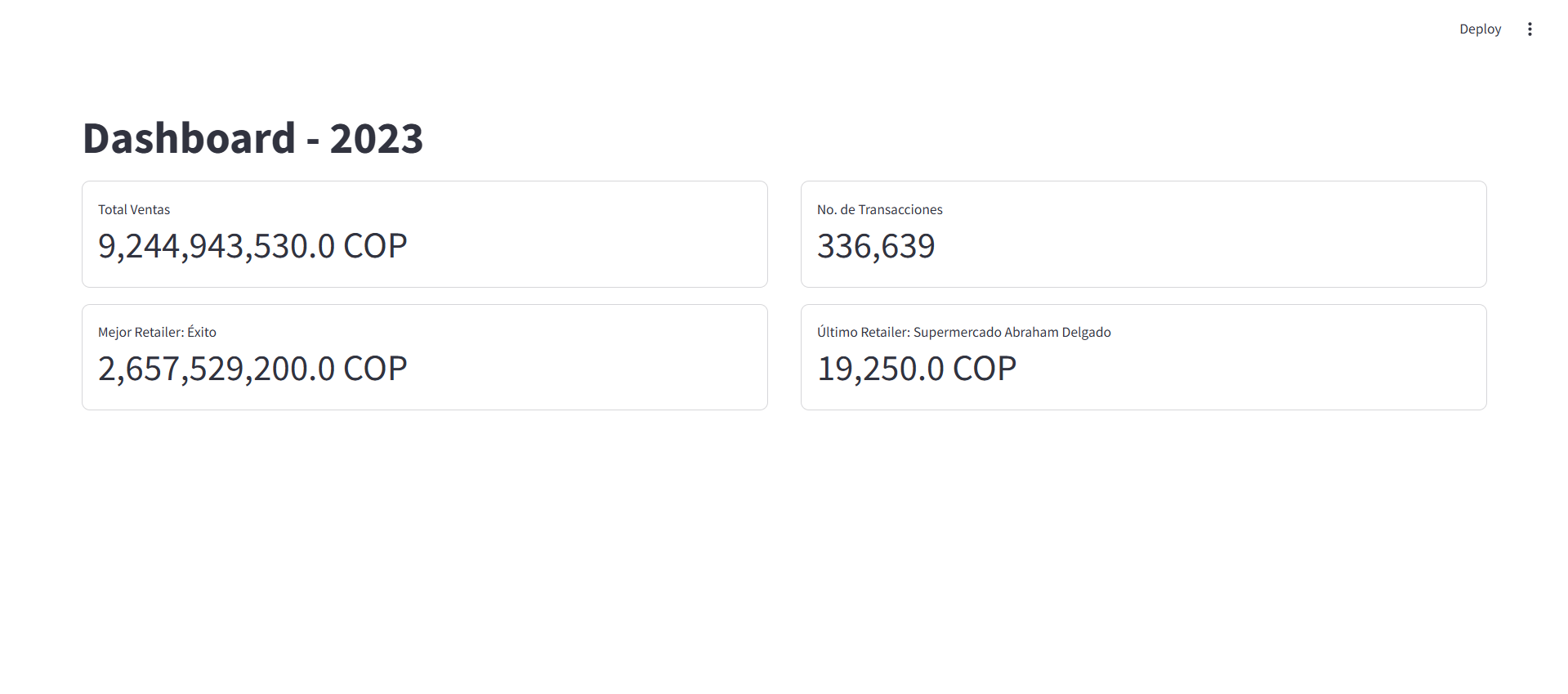 Dashboard - Sección Inicial
Dashboard - Sección Inicial
2. Sección de Gráficos con Porcentaje de Ventas por Retail y Categoría
Luego de agregar nuestra sección inicial, vamos a crear una nueva sección destinada a visualizar el porcentaje de ventas por Retail y Categoría. Para ello, vamos a utilizar gráficos de pastel que nos permitan identificar los retailers y categorías.
app.py
st.subheader("Porcentaje de Ventas x Retailer y Categoria") col_1, col_2 = st.columns(2,gap='medium') with col_1: st.text("Se muestran los retailers que ocupan un porcentaje mayor al 2%") # Filtrar los retailers que ocupan un porcentaje menor al 2% sales_by_retailer['PERCENT'] = sales_by_retailer['VENTAS'] / sales_by_retailer['VENTAS'].sum() * 100 filtered_sales_by_retailer = sales_by_retailer[sales_by_retailer['PERCENT'] >= 2] # Crear el gráfico de pastel fig = px.pie(filtered_sales_by_retailer, values='VENTAS', names='RETAILER') st.plotly_chart(fig) with col_2: # Calcular y mostrar las ventas por categoría sales_by_category = df.groupby('CATEGORIA_3')['VENTAS'].sum().reset_index() fig = px.pie(sales_by_category, values='VENTAS', names='CATEGORIA_3') st.plotly_chart(fig)
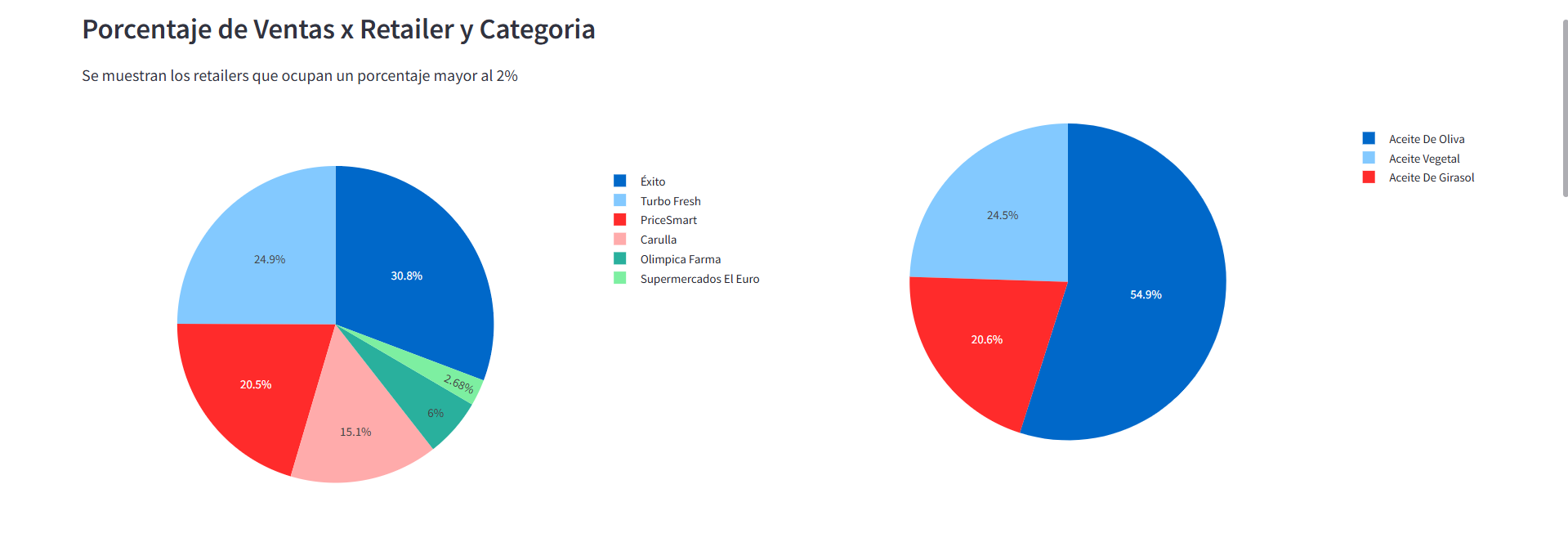 Dashboard - Sección de Gráficos de Pastel
Dashboard - Sección de Gráficos de Pastel
3. Rendimiento de las Ventas por Mes
En esta sección, vamos a visualizar el rendimiento de las ventas por mes en 2023. Para ello, vamos a utilizar un gráfico de barras que nos permita identificar el comportamiento de las ventas mes a mes a lo largo del año y algunas métricas clave.
app.py
st.subheader("Rendimiento de las Ventas por Mes") col_1, col_2 = st.columns(2,gap='medium') with col_1: # Calcular y mostrar las ventas por mes sales_by_month = df.groupby('MES')['VENTAS'].sum().reset_index() # Diccionario con los nombres de los meses months_dictionary = { '01':'Enero', '02':'Febrero', '03':'Marzo', '04':'Abril', '05':'Mayo', '06':'Junio', '07':'Julio', '08':'Agosto', '09':'Septiembre', '10':'Octubre', '11':'Noviembre', '12':'Diciembre' } # Cambiar el formato de los meses a texto sales_by_month['MES'] = sales_by_month['MES'].map(months_dictionary) # Creamos una figur que muestre las ventas por mes en un gráfico de barras fig = px.bar(sales_by_month, x='MES', y='VENTAS', title='Ventas por Mes') # Agregar una línea que muestre el comportamiento de las ventas fig.add_scatter( x=sales_by_month['MES'], y=sales_by_month['VENTAS'], name='Tendencia', # Nombre de la línea line=dict(color='red', width=2) ) st.plotly_chart(fig) with col_2: # Mostrar las métricas de las ventas por mes st.metric( value=f"{sales_by_month['VENTAS'].mean():,.2f} COP", label="Promedio de Ventas", border=True ) st.metric( value=f"{sales_by_month['VENTAS'].max():,.2f} COP", label=f"Mejor Mes: {sales_by_month['MES'][sales_by_month['VENTAS'].idxmax()]}", border=True ) st.metric( value=f"{sales_by_month['VENTAS'].min():,.2f} COP", label=f"Mes con menos Ventas: {sales_by_month['MES'][sales_by_month['VENTAS'].idxmin()]}", border=True )
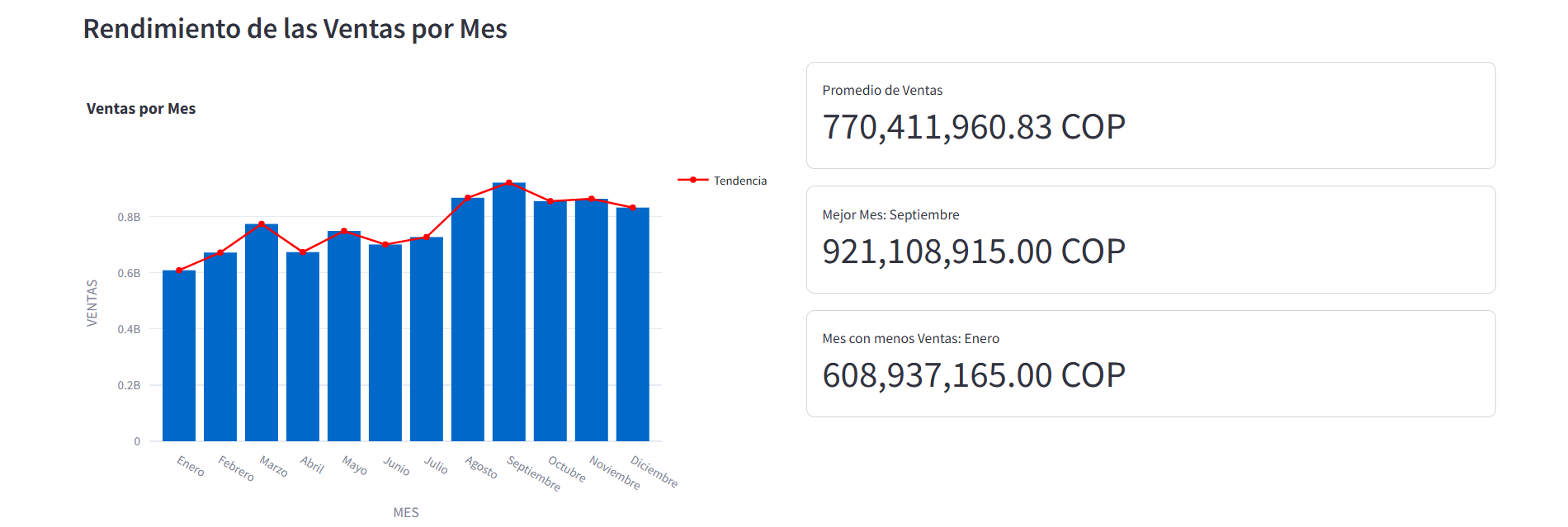 Dashboard - Sección de Rendimiento de las Ventas por Mes
Dashboard - Sección de Rendimiento de las Ventas por Mes
Además vamos a agregar una selectbox que nos permita filtrar las ventas por mes de cada uno de los retailers.
app.py
# Agregar un selector para elegir un retailer retailer = st.selectbox( options=df['RETAILER'].unique(), # Opciones del selector label='Selecciona un Retailer' )
Finalmente, vamos a filtrar las ventas por retailer y mostrar un gráfico de barras con las ventas por mes del retailer seleccionado y algunas métricas clave como el promedio de ventas, el mejor mes y el mes con menos ventas.
app.py
# Filtrar las ventas por retailer retailer_sales_by_month = df[df['RETAILER'] == retailer].groupby('MES')['VENTAS'].sum().reset_index() col_1, col_2 = st.columns(2,gap='medium') with col_1: # Cambiar el formato de los meses a texto retailer_sales_by_month['MES'] = retailer_sales_by_month['MES'].map(months_dictionary) # Crear un gráfico de barras con las ventas por mes del retailer seleccionado fig = px.bar(retailer_sales_by_month,x='MES', y='VENTAS', title=f"Ventas x Mes {retailer}") fig.add_scatter( x=retailer_sales_by_month['MES'], y=retailer_sales_by_month['VENTAS'], name='Tendencia', # Nombre de la línea line=dict(color='red', width=2) ) st.plotly_chart(fig) with col_2: # Mostrar las métricas de las ventas por mes del retailer seleccionado st.metric( value=f"{retailer_sales_by_month['VENTAS'].mean():,.2f} COP", label="Promedio de Ventas", border=True ) st.metric( value=f"{retailer_sales_by_month['VENTAS'].max():,.2f} COP", label=f"Mejor Mes: {retailer_sales_by_month['MES'][retailer_sales_by_month['VENTAS'].idxmax()]}", border=True ) st.metric( value=f"{retailer_sales_by_month['VENTAS'].min():,.2f} COP", label=f"Mes con menos Ventas: {retailer_sales_by_month['MES'][retailer_sales_by_month['VENTAS'].idxmin()]}", border=True )
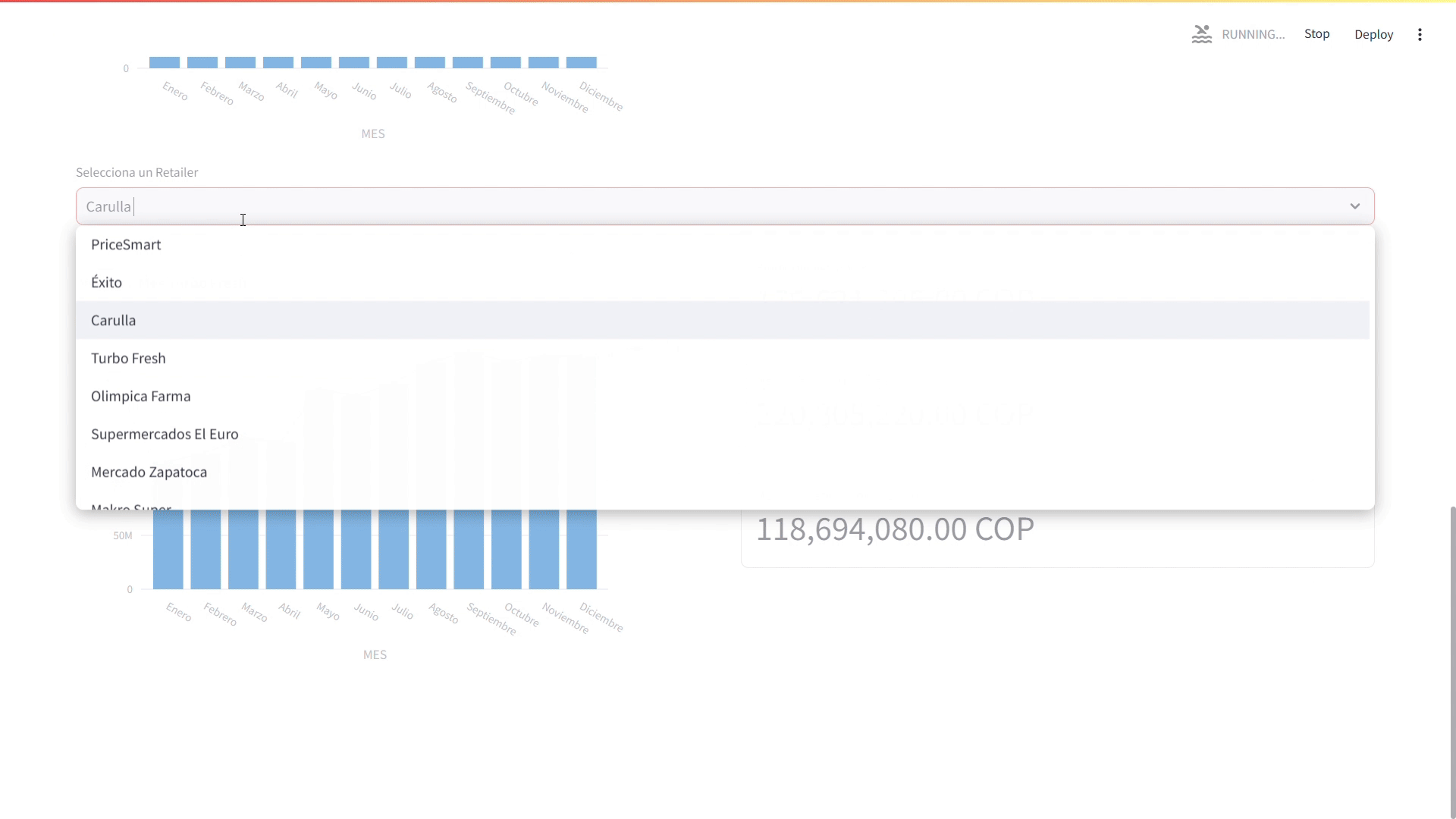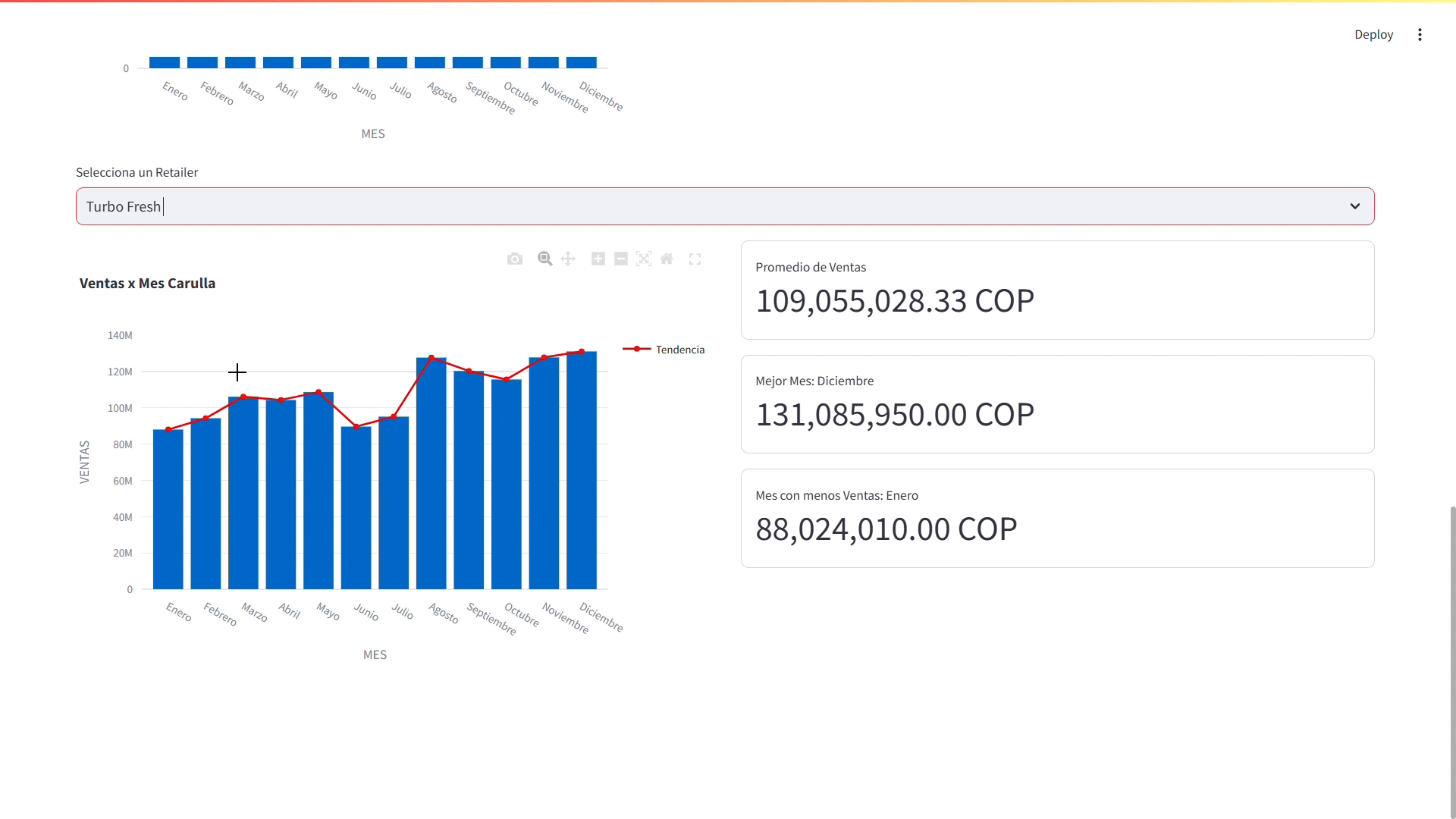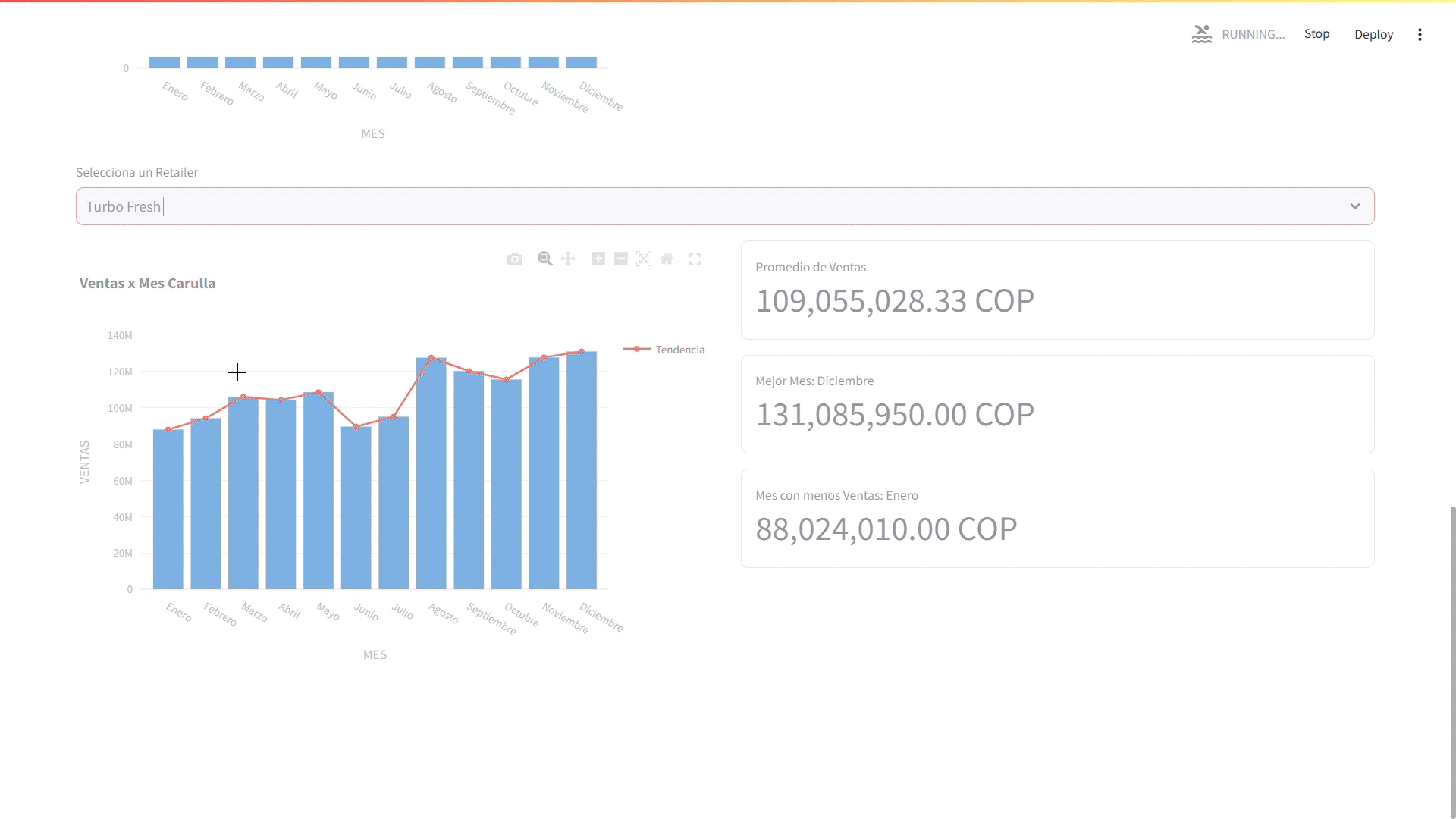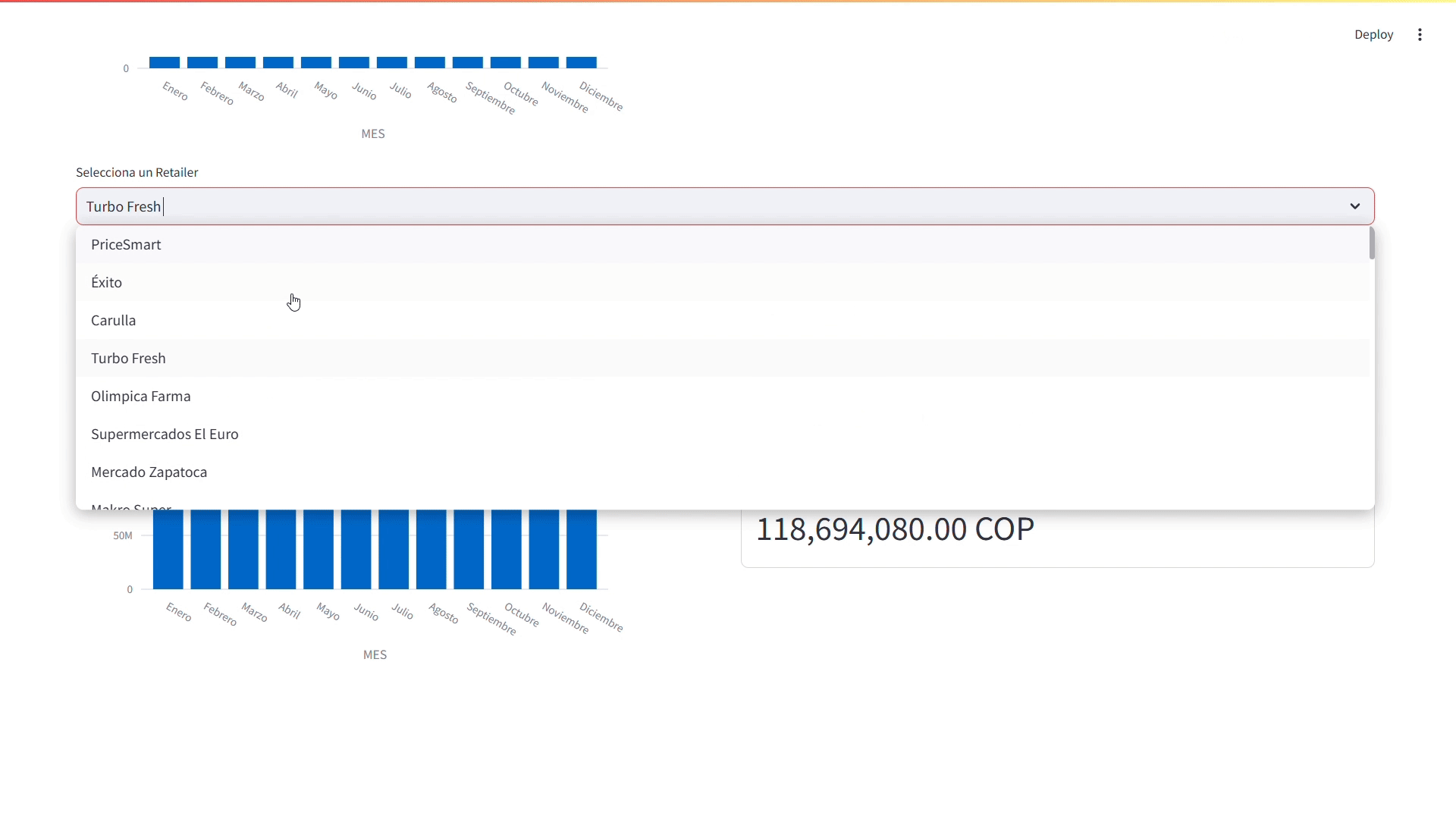 Dashboard - Sección de Rendimiento de las Ventas por Mes
Dashboard - Sección de Rendimiento de las Ventas por Mes
4. Sección de Análisis por Día de la Semana
Con el fin de poder identificar el mejor día de la semana para enfocar las estrategias, vamos a crear una sección en el Dashboard que nos permita visualizar las ventas por día de la semana.
app.py
st.subheader("Ventas x Días de la Semana") col_1, col_2 = st.columns(2,gap='medium') # Calcular y mostrar las ventas por día de la semana sales_by_day = df.groupby('DAY_NAME')['VENTAS'].sum().reset_index() with col_1: fig = px.bar(sales_by_day, x='DAY_NAME', y='VENTAS', title='Ventas por Día de la Semana') # Agregar una línea que muestre el comportamiento de las ventas fig.add_scatter( x=sales_by_day['DAY_NAME'], y=sales_by_day['VENTAS'], name='Tendencia', line=dict(color='red', width=2) ) st.plotly_chart(fig) with col_2: # Mostrar las métricas de las ventas por día de la semana st.metric( value=f"{sales_by_day['VENTAS'].mean():,.2f} COP", label="Promedio de Ventas", border=True ) st.metric( value=f"{sales_by_day['VENTAS'].max():,.2f} COP", label=f"Mejor Día: {sales_by_day['DAY_NAME'][sales_by_day['VENTAS'].idxmax()]}", border=True ) st.metric( value=f"{sales_by_day['VENTAS'].min():,.2f} COP", label=f"Día con menos Ventas: {sales_by_day['DAY_NAME'][sales_by_day['VENTAS'].idxmin()]}", border=True )
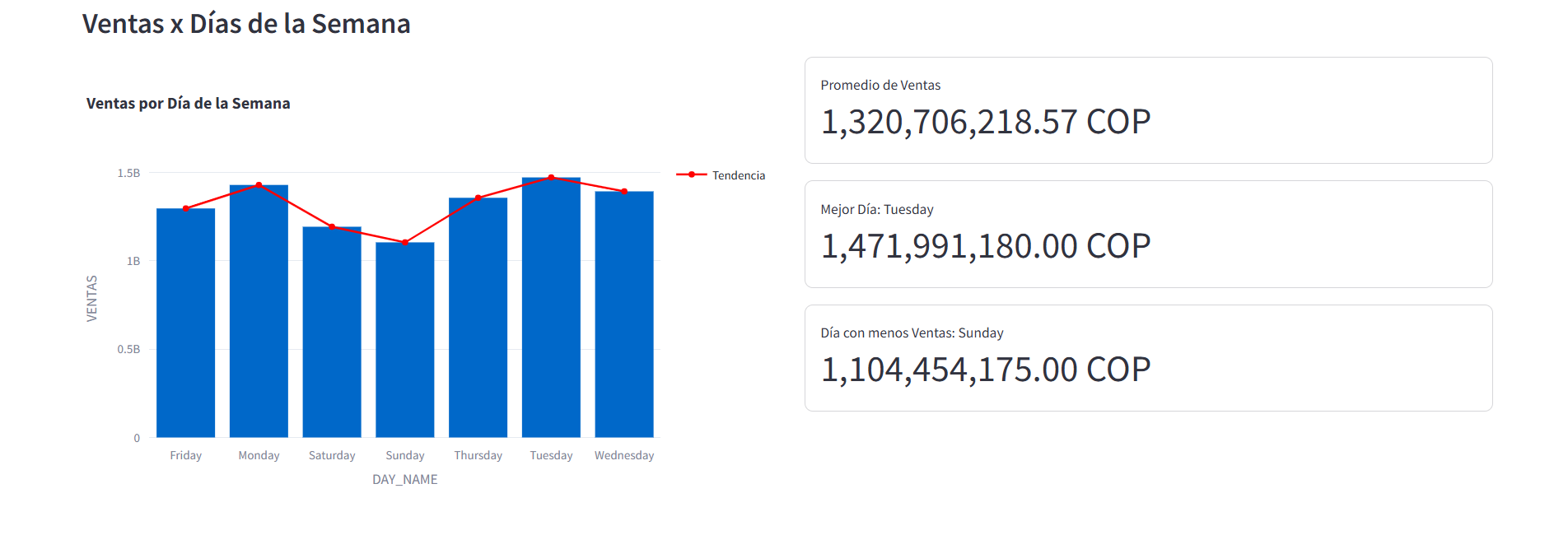 Dashboard - Sección de Análisis por Día de la Semana
Dashboard - Sección de Análisis por Día de la Semana
Una vez hemos finalizado la construcción del Dashboard, podemos ejecutar la aplicación y visualizar los resultados obtenidos.
streamlit run app.py
Si quieres ver todo el código completo de app.py lo puede ver en el siguiente enlace.
Análisis
Una vez hemos finalizado la construcción de nuestro Dashboard en Streamlit, podemos analizar los resultados obtenidos y responder las preguntas planteadas en la sección de métricas clave. A continuación, algunas conclusiones que podemos obtener del análisis del Dashboard:
- Rendimiento de las Ventas en 2023: El total de ventas en 2023 fue de
9,244,943,530.0 COP. Donde la cadena de SupermercadosExitofue el retailer con mayor porcentaje en el total de ventas con un30.8%y la categoría deAceites de Olivafue la categoría con mayor porcentaje en el total de ventas con un54.9%. - Mejor Día de la Semana: El mejor día de la semana para enfocar las estrategias fue el
Juevescon un total de ventas de1,471,991,180.00 COPa lo largo del año durante este día. Así mismo, el día con menos ventas fue elViernescon un total de ventas de1,104,454,175.00 COP.
Conclusiones
A partir de esta información, podemos comenzar a diseñar un plan estratégico para 2024 que maximice el rendimiento y aproveche las oportunidades detectadas en 2023. Algunas recomendaciones que podríamos plantear son:
- Enfocar las estrategias en el Retailer
Exito: Dado queExitofue el retailer con mayor porcentaje en el total de ventas, podríamos enfocar nuestras estrategias en este retailer para maximizar el rendimiento en 2024. Además podriamos enfocar nuestras estrategias en la categoría deAceites de Olivaque fue la categoría con mayor porcentaje en el total de ventas. - Enfocar las estrategias en el Día
Jueves: Dado que elJuevesfue el mejor día de la semana para enfocar las estrategias, podríamos diseñar campañas y promociones especiales para este día con el fin de aumentar las ventas en 2024. - Dependencia del
Exito: Dado queExitofue el retailer con mayor porcentaje en el total de ventas, es importante tener en cuenta que una dependencia excesiva de un único retailer puede ser un riesgo para el negocio. Por lo tanto, es importante diversificar la estrategia y explorar oportunidades en otros retailers.
Despliegue del Dashboard
Para desplegar nuestro dashboard de Streamlit, una de las posibles opciones que podemos utilizar es la plataforma Streamlit Community Cloud, donde podemos desplegar nuestra aplicación de manera gratuita y de forma sencilla. Para ello debemos seguir los siguientes pasos:
-
Crear una cuenta en Streamlit Community Cloud, puedes crearla con tu cuenta de GitHub lo cual facilitará el proceso de despliegue.
-
Crear un nuevo repositorio en GitHub y sube el código de tu aplicación de Streamlit.
-
Selecciona la opción
Create Appen la plataforma de Streamlit Community Cloud.
 Crea una nueva aplicación en Streamlit Community Cloud
Crea una nueva aplicación en Streamlit Community Cloud
-
Selecciona la opción
Deploy a public App from GitHub. -
Finalmente, selecciona el repositorio de GitHub donde se encuentra tu aplicación de Streamlit e ingresa el nombre del archivo de tu aplicación. En este caso, el nombre del archivo es
app.py. Finalmente, selecciona la rama de tu repositorio y haz clic enDeploy.
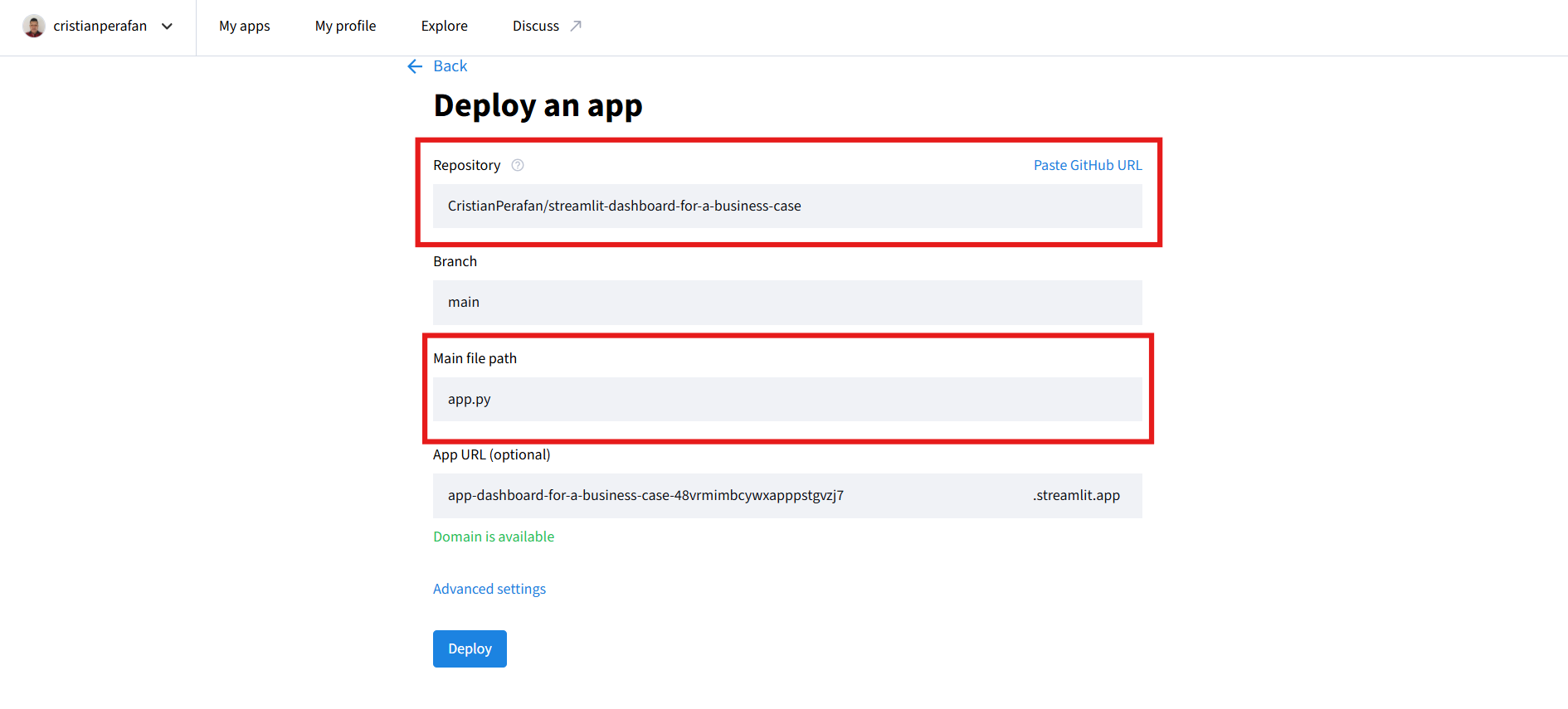 Despliega tu aplicación de Streamlit en Streamlit Community Cloud
Despliega tu aplicación de Streamlit en Streamlit Community Cloud
Si quieres ver mi aplicación de Streamlit desplegada en Streamlit Community Cloud, puedes acceder al siguiente enlace.
¡Felicidades! 🎉 Has creado un Dashboard en Streamlit para un caso de negocio. Ahora puedes explorar y analizar los datos de manera interactiva y tomar decisiones estratégicas basadas en la información obtenida.
El código completo de la aplicación de Streamlit lo puedes encontrar en el siguiente repositorio de GitHub